Maze Navigation
Using the same components as we did in the Team Battle tutorial, we can create a Maze Navigation Simulation that contains a single moving agent navigating a maze defined by wall agents in the grid. The moving agent’s goal is to reach a target agent. We will construct the Grid by reading a grid file. This tutorial can be found in full in our repo.
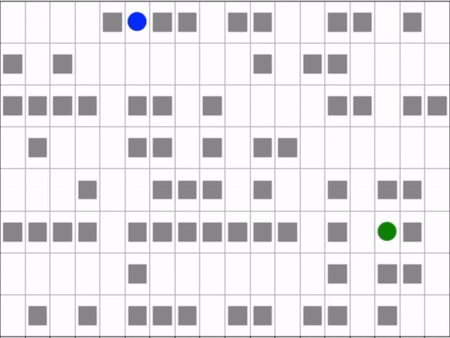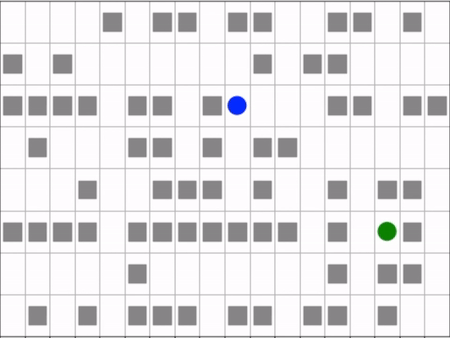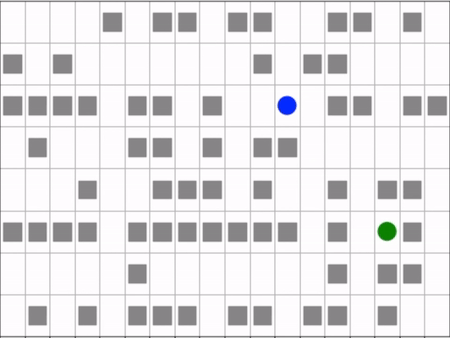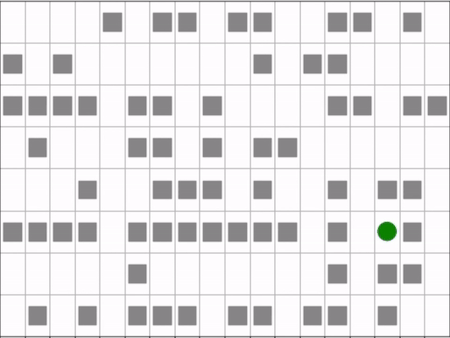
Agent (blue) navigating a maze to the target (green).
Note
While we have multiple entities like walls and a target agent, the only agent that is actually doing something is the navigation agent. We will use some custom modifications to make this simulation easier, showing that we can easily use our components with custom modifications.
First we import the components that we need. Each feature is already in Abmarl, and they are the same features that we used in the Team Battle tutorial.
from matplotlib import pyplot as plt
import numpy as np
from abmarl.sim.gridworld.base import GridWorldSimulation
from abmarl.sim.gridworld.agent import GridObservingAgent, MovingAgent, GridWorldAgent
from abmarl.sim.gridworld.state import PositionState
from abmarl.sim.gridworld.actor import MoveActor
from abmarl.sim.gridworld.observer import PositionCenteredEncodingObserver
Then, we define our agent types. We need an MazeNavigationAgent, WallAgents to act as the barriers of the maze, and a TargetAgent to indicate the goal. Although we have these three types, we only need to define the MazeNavigationAgent because the WallAgent and the TargetAgent are the same as a generic GridWorldAgent.
class MazeNavigationAgent(GridObservingAgent, MovingAgent):
def __init__(self, **kwargs):
super().__init__(move_range=1, **kwargs)
Here we have preconfigured the agent with a move range of 1 becuase that makes the most sense for navigating mazes, but we have not preconfigured the view range since that is a parameter we may want to adjust, and it is easier to adjust it at the agent’s initialization.
Then we define the simulation using the components and define all the necessary functions. We find it convient to explicitly store a reference to the navigation agent and the target agent. Rather than defining a new component for our simple done condition, we just write the condition itself in the function.
class MazeNaviationSim(GridWorldSimulation):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Store the navigation and target agents
self.navigator = self.agents['navigator']
self.target = self.agents['target']
# State Components
self.position_state = PositionState(**kwargs)
# Action Components
self.move_actor = MoveActor(**kwargs)
# Observation Components
self.grid_observer = PositionCenteredEncodingObserver(**kwargs)
self.finalize()
def reset(self, **kwargs):
self.position_state.reset(**kwargs)
# Since there is only one agent that produces actions, there is only one reward.
self.reward = 0
def step(self, action_dict, **kwargs):
# Only the navigation agent will send actions, so we pull that out
action = action_dict['navigator']
move_result = self.move_actor.process_action(self.navigator, action, **kwargs)
if not move_result:
self.reward -= 0.1
# Entropy penalty
self.reward -= 0.01
def get_obs(self, agent_id, **kwargs):
# pass the navigation agent itself to the observer becuase it is the only
# agent that takes observations
return {
**self.grid_observer.get_obs(self.navigator, **kwargs)
}
def get_reward(self, agent_id, **kwargs):
# Custom reward function
if self.get_all_done():
self.reward = 1
reward = self.reward
self.reward = 0
return reward
def get_done(self, agent_id, **kwargs):
return self.get_all_done()
def get_all_done(self, **kwargs):
# We define the done condition here directly rather than creating a
# separate component for it.
return np.all(self.navigator.position == self.target.position)
def get_info(self, agent_id, **kwargs):
return {}
With everything defined, we’re ready to create and run our simulation. We will create the simulation by reading a simulation file that shows the positions of each agent type in the grid. We will use maze.txt, which looks like this:
_ _ _ _ W _ W W _ W W _ _ W W _ W _
W _ W _ N _ _ _ _ _ W _ W W _ _ _ _
W W W W _ W W _ W _ _ _ _ W W _ W W
_ W _ _ _ W W _ W _ W W _ _ _ _ _ _
_ _ _ W _ _ W W W _ W _ _ W _ W W _
W W W W _ W W W W W W W _ W _ T W _
_ _ _ _ _ W _ _ _ _ _ _ _ W _ W W _
_ W _ W _ W W W _ W W _ W W _ W _ _
In order to assign meaning to the values in the grid file, we must create an object
registry that maps the values in the files to objects. We will use W for WallAgents,
N for the NavigationAgent, and T for the TargetAgent. The values of the
object registry must be lambda functions that take one argument and produce an agent.
object_registry = {
'N': lambda n: MazeNavigationAgent(
id=f'navigator',
encoding=1,
view_range=2, # Observation parameter that we can adjust as desired
render_color='blue',
),
'T': lambda n: GridWorldAgent(
id=f'target',
encoding=3,
render_color='green'
),
'W': lambda n: GridWorldAgent(
id=f'wall{n}',
encoding=2,
blocking=True,
render_shape='s'
)
}
Now we can build the simulation from the maze file using the object registry. We must allow the navigation agent and the target agent to overlap since that is our done condition, and without it the simulation would never end. The visualization produces an animation like the one at the top of this page.
file_name = 'maze.txt'
sim = MazeNaviationSim.build_sim_from_file(
file_name,
object_registry,
overlapping={1: {3}, 3: {1}}
)
sim.reset()
fig = plt.figure()
sim.render(fig=fig)
for i in range(100):
action = {'navigator': sim.navigator.action_space.sample()}
sim.step(action)
sim.render(fig=fig)
done = sim.get_all_done()
if done:
plt.pause(1)
break
We can examine the observation to see how the walls effect what the navigation agent can observe. An example state and observation is given below.

-1 -2 -2 -2 -1
0 0 2 0 2
2 0 1 0 0
-2 2 0 2 -2
-2 -2 0 -2 -2
Extra Challenges
We’ve created a starkly different simulation using many of the same components as we did in the TeamBattle tutorial. We can further explore the capabilities of the GridWorld Simulation Framework, such as:
Introduce additional navigating agents and modify the simulation so that the agents race to the target.
Recreate pacman, frogger, and some of your favorite games from the Arcade Learning Environment. Not all games can be recreated with these components, and some cannot be recreated at all with the GridWorld Simulation Framework (because they are not grid-based).
Connect this simulation with the Reinforcement Learning capabilities of Abmarl via a Simulation Manager. Does the agent learng how to solve mazes quickly?
And much, much more!