Design¶
A reinforcement learning experiment in Abmarl contains two interacting components: a Simulation and a Trainer.
The Simulation contains agent(s) who can observe the state (or a substate) of the Simulation and whose actions affect the state of the simulation. The simulation is discrete in time, and at each time step agents can provide actions. The simulation also produces rewards for each agent that the Trainer can use to train optimal behaviors. The Agent-Simulation interaction produces state-action-reward tuples (SARs), which can be collected in rollout fragments and used to optimize agent behaviors.
The Trainer contains policies that map agents’ observations to actions. Policies are one-to-many with agents, meaning that there can be multiple agents using the same policy. Policies may be heuristic (i.e. coded by the researcher) or trainable by the RL algorithm.
In Abmarl, the Simulation and Trainer are specified in a single Python configuration file. Once these components are set up, they are passed as parameters to RLlib’s tune command, which will launch the RLlib application and begin the training process. The training process will save checkpoints to an output directory, from which the user can visualize and analyze results. The following diagram demonstrates this workflow.
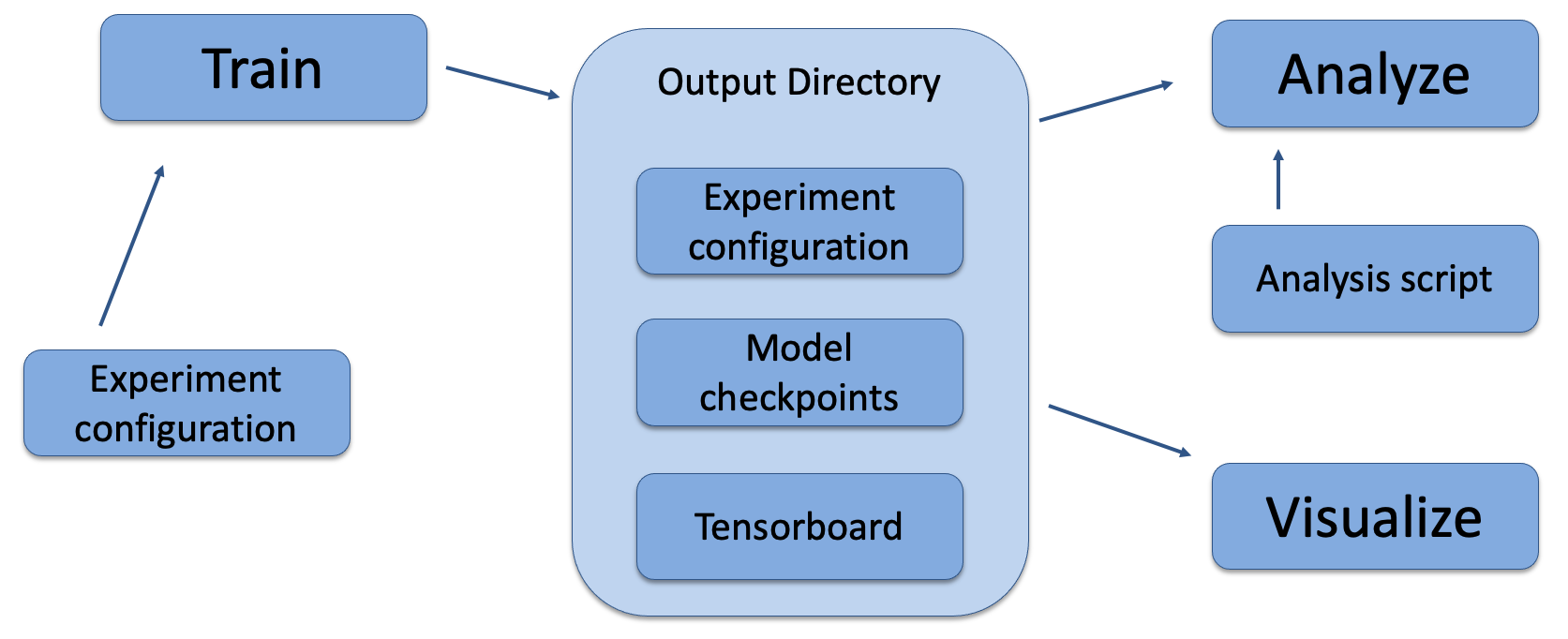
Abmarl’s usage workflow. An experiment configuration is used to train agents’ behaviors. The policies and simulation are saved to an output directory. Behaviors can then be analyzed or visualized from the output directory.¶
Creating Agents and Simulations¶
Abmarl provides three interfaces for setting up an agent-based simulations.
Agent¶
First, we have Agents. An agent is an object with an observation and action space. Many practitioners may be accustomed to gym.Env’s interface, which defines the observation and action space for the simulation. However, in heterogeneous multiagent settings, each agent can have different spaces; thus we assign these spaces to the agents and not the simulation.
An agent can be created like so:
from gym.spaces import Discrete, Box
from abmarl.sim import Agent
agent = Agent(
id='agent0',
observation_space=Box(-1, 1, (2,)),
action_space=Discrete(3)
)
At this level, the Agent is basically a dataclass. We have left it open for our users to extend its features as they see fit.
Agent Based Simulation¶
Next, we define an Agent Based Simulation, or ABS for short, with the
ususal reset and step
functions that we are used to seeing in RL simulations. These functions, however, do
not return anything; the state information must be obtained from the getters:
get_obs, get_reward, get_done, get_all_done, and get_info. The getters
take an agent’s id as input and return the respective information from the simulation’s
state. The ABS also contains a dictionary of agents that “live” in the simulation.
An Agent Based Simulation can be created and used like so:
from abmarl.sim import Agent, AgentBasedSimulation
class MySim(AgentBasedSimulation):
def __init__(self, agents=None, **kwargs):
self.agents = agents
... # Implement the ABS interface
# Create a dictionary of agents
agents = {f'agent{i}': Agent(id=f'agent{i}', ...) for i in range(10)}
# Create the ABS with the agents
sim = MySim(agents=agents)
sim.reset()
# Get the observations
obs = {agent.id: sim.get_obs(agent.id) for agent in agents.values()}
# Take some random actions
sim.step({agent.id: agent.action_space.sample() for agent in agents.values()})
# See the reward for agent3
print(sim.get_reward('agent3'))
Warning
Implementations of AgentBasedSimulation should call finalize at the
end of its __init__. Finalize ensures that all agents are configured and
ready to be used for training.
Note
Instead of treating agents as dataclasses, we could have included the relevant
information in the Agent Based Simulation with various dictionaries. For example,
we could have action_spaces and observation_spaces that
maps agents’ ids to their action spaces and observation spaces, respectively.
In Abmarl, we favor the dataclass approach and use it throughout the package
and documentation.
Simulation Managers¶
The Agent Based Simulation interface does not specify an ordering for agents’ interactions
with the simulation. This is left open to give our users maximal flexibility. However,
in order to interace with RLlib’s learning library, we provide a Simulation Manager
which specifies the output from reset and step as RLlib expects it. Specifically,
Agents that appear in the output dictionary will provide actions at the next step.
Agents that are done on this step will not provide actions on the next step.
Simulation managers are open-ended requiring only reset and step with output
described above. For convenience, we have provided two managers: Turn Based,
which implements turn-based games; and All Step, which has every non-done
agent provide actions at each step.
Simluation Managers “wrap” simulations, and they can be used like so:
from abmarl.managers import AllStepManager
from abmarl.sim import AgentBasedSimulation, Agent
class MySim(AgentBasedSimulation):
... # Define some simulation
# Instatiate the simulation
sim = MySim(agents=...)
# Wrap the simulation with the simulation manager
sim = AllStepManager(sim)
# Get the observations for all agents
obs = sim.reset()
# Get simulation state for all non-done agents, regardless of which agents
# actually contribute an action.
obs, rewards, dones, infos = sim.step({'agent0': 4, 'agent2': [-1, 1]})
External Integration¶
In order to train agents in a Simulation Manager using RLlib, we must wrap the simulation with either a GymWrapper for single-agent simulations (i.e. only a single entry in the agents dict) or a MultiAgentWrapper for multiagent simulations.
Training with an Experiment Configuration¶
In order to run experiments, we must define a configuration file that specifies Simulation and Trainer parameters. Here is the configuration file from the Corridor tutorial that demonstrates a simple corridor simulation with multiple agents.
# Import the MultiCorridor ABS, a simulation manager, and the multiagent
# wrapper needed to connect to RLlib's trainers
from abmarl.sim.corridor import MultiCorridor
from abmarl.managers import TurnBasedManager
from abmarl.external import MultiAgentWrapper
# Create and wrap the simulation
# NOTE: The agents in `MultiCorridor` are all homogeneous, so this simulation
# just creates and stores the agents itself.
sim = MultiAgentWrapper(TurnBasedManager(MultiCorridor()))
# Register the simulation with RLlib
sim_name = "MultiCorridor"
from ray.tune.registry import register_env
register_env(sim_name, lambda sim_config: sim)
# Set up the policies. In this experiment, all agents are homogeneous,
# so we just use a single shared policy.
ref_agent = sim.unwrapped.agents['agent0']
policies = {
'corridor': (None, ref_agent.observation_space, ref_agent.action_space, {})
}
def policy_mapping_fn(agent_id):
return 'corridor'
# Experiment parameters
params = {
'experiment': {
'title': f'{sim_name}',
'sim_creator': lambda config=None: sim,
},
'ray_tune': {
'run_or_experiment': 'PG',
'checkpoint_freq': 50,
'checkpoint_at_end': True,
'stop': {
'episodes_total': 2000,
},
'verbose': 2,
'config': {
# --- simulation ---
'env': sim_name,
'horizon': 200,
'env_config': {},
# --- Multiagent ---
'multiagent': {
'policies': policies,
'policy_mapping_fn': policy_mapping_fn,
},
# --- Parallelism ---
"num_workers": 7,
"num_envs_per_worker": 1,
},
}
}
Warning
The simulation must be a Simulation Manager or an External Wrapper as described above.
Note
This example has num_workers set to 7 for a computer with 8 CPU’s.
You may need to adjust this for your computer to be <cpu count> - 1.
Experiment Parameters¶
The strucutre of the parameters dictionary is very important. It must have an experiment key which contains both the title of the experiment and the sim_creator function. This function should receive a config and, if appropriate, pass it to the simulation constructor. In the example configuration above, we just retrun the already-configured simulation. Without the title and simulation creator, Abmarl may not behave as expected.
The experiment parameters also contains information that will be passed directly to RLlib via the ray_tune parameter. See RLlib’s documentation for a list of common configuration parameters.
Command Line¶
With the configuration file complete, we can utilize the command line interface
to train our agents. We simply type abmarl train multi_corridor_example.py,
where multi_corridor_example.py is the name of our configuration file. This will launch
Abmarl, which will process the file and launch RLlib according to the
specified parameters. This particular example should take 1-10 minutes to
train, depending on your compute capabilities. You can view the performance
in real time in tensorboard with tensorboard --logdir ~/abmarl_results.
Visualizing¶
We can visualize the agents’ learned behavior with the visualize command, which
takes as argument the output directory from the training session stored in
~/abmarl_results. For example, the command
abmarl visualize ~/abmarl_results/MultiCorridor-2020-08-25_09-30/ -n 5 --record
will load the experiment (notice that the directory name is the experiment
title from the configuration file appended with a timestamp) and display an animation
of 5 episodes. The --record flag will save the animations as .mp4 videos in
the training directory.
Analyzing¶
The simulation and trainer can also be loaded into an analysis script for post-processing via the
analyze command. The analysis script must implement the following run function.
Below is an example that can serve as a starting point.
# Load the simulation and the trainer from the experiment as objects
def run(sim, trainer):
"""
Analyze the behavior of your trained policies using the simulation and trainer
from your RL experiment.
Args:
sim:
Simulation Manager object from the experiment.
trainer:
Trainer that computes actions using the trained policies.
"""
# Run the simulation with actions chosen from the trained policies
policy_agent_mapping = trainer.config['multiagent']['policy_mapping_fn']
for episode in range(100):
print('Episode: {}'.format(episode))
obs = sim.reset()
done = {agent: False for agent in obs}
while True: # Run until the episode ends
# Get actions from policies
joint_action = {}
for agent_id, agent_obs in obs.items():
if done[agent_id]: continue # Don't get actions for done agents
policy_id = policy_agent_mapping(agent_id)
action = trainer.compute_action(agent_obs, policy_id=policy_id)
joint_action[agent_id] = action
# Step the simulation
obs, reward, done, info = sim.step(joint_action)
if done['__all__']:
break
Analysis can then be performed using the command line interface:
abmarl analyze ~/abmarl_results/MultiCorridor-2020-08-25_09-30/ my_analysis_script.py
See the Predator Prey tutorial for an example of analyzing trained agent behavior.
Running at scale with HPC¶
Abmarl also supports some functionality for training at scale. See the magpie tutorial, which provides a walkthrough for launching a training experiment on multiple compute nodes with slurm.